
GIS data, like any other information, isn’t flawless. It may contain errors or inaccuracies that can impact GIS analysis outcomes. Some common sources of errors in GIS data include incomplete or outdated data sources, mistakes in data entry or conversion, imprecise or inaccurate measurements, and inherent limitations in the data collection method.
For those working with GIS data, it’s crucial to grasp that errors, inaccuracies, and imprecision can significantly affect the quality of various GIS projects. Unaccounted errors can render GIS analyses ineffective. Understanding the inherent errors in GIS data is essential to ensure that spatial analyses using these datasets meet a minimum threshold for accuracy. The saying “Garbage in, garbage out” strongly applies when using inaccurate, imprecise, or error-filled data during analysis.
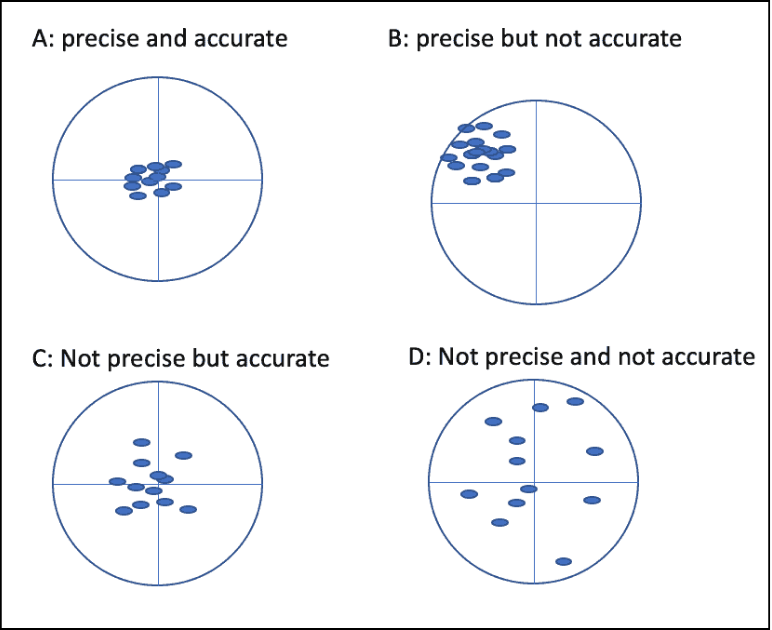
Accuracy and Precision
The strength of GIS lies in its ability to integrate various data types related to the same geographical area within a single system for analysis. When a new dataset is introduced into a GIS software application, the software imports not only the data but also the errors within it. Addressing the problem of error starts with being aware of it and understanding the limitations of the data in use.
Accuracy and precision are both vital aspects of GIS data quality, but they refer to different concepts. Accuracy is defined as the degree of closeness to which the information on a map matches real-world values. In GIS data, accuracy can refer to geographic position, attribute, or conceptual accuracy. On the other hand, precision refers to how exact the description of data is. Precise data may be inaccurately gathered, such as when a surveyor makes a mistake or data is recorded wrongly into the database.
In a series of images, the difference between precision and accuracy is visualized. Image A is both precise and accurate, Image B is precise but not accurate, Image C is accurate but imprecise, and Image D is neither accurate nor precise. Understanding both accuracy and precision is crucial for assessing the usability of a GIS dataset. When a dataset is inaccurate but highly precise, corrective measures can be taken to adjust the dataset and make it more accurate.
Sources of Inaccuracy and Imprecision
Some sources of error in GIS data are obvious, while others are more challenging to notice. GIS software may lead users to believe that their data is more accurate and precise than it actually is. Scale is an inherent error in cartography, influencing data representation based on the chosen scale.
The age of data is another clear source of error. When data sources are too old, a significant part of the information base may have changed. GIS users must be cautious when using old data and consider its lack of currency before applying it to contemporary analysis.
GIS Data Formatting Errors
Errors can arise during data formatting for processing, including changes in scale, reprojections, and import/export from raster to vector. Other errors may originate during initial measurements or data capture by users.
Attribute errors, such as labeling mistakes, are common. For instance, an agricultural land may be incorrectly marked as a marsh, causing an error that the map user may not notice if they are unfamiliar with the area. Quantitative errors can occur when instruments are not properly calibrated, introducing hard-to-identify errors in the field and compromising project accuracy and reliability.
Positional Accuracy of GIS Data
Attention must be paid to positional accuracy, which is dependent on the type of data. While certain features like roads and boundary lines can be accurately located by cartographers, other data with less defined positions, such as soil types, may only have an approximate location based on the cartographer’s estimation.

Topological Errors
Topological errors often occur during the digitizing process. Errors during digitization or GIS data creation may result in polygon knots, weird polygons, and loops. Damaged source maps can also introduce errors.
Intentional GIS Data Errors
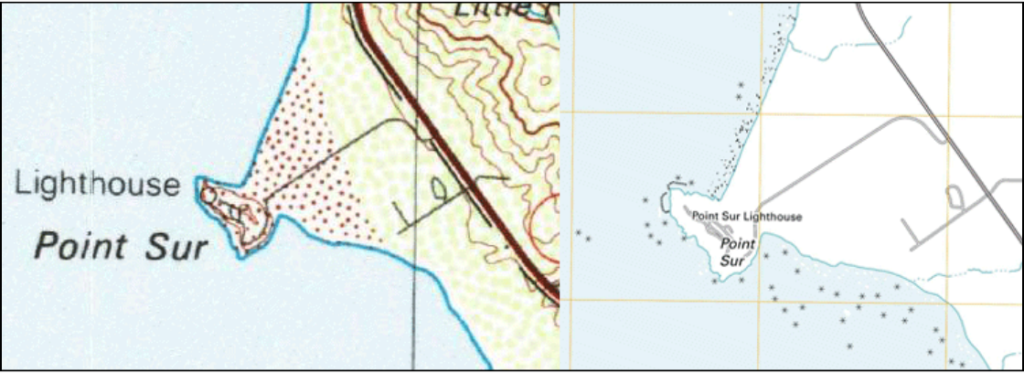
Errors can be intentionally introduced into GIS data. Generalization, a common practice in GIS, reduces the amount of detail in a dataset and introduces error by removing aspects of a feature. Another intentional introduction of error is trademarking, where commercial GIS vendors may insert false streets or fake street names into a dataset, known as a “map trap.”
Always Factor in Potential Errors
In GIS projects using more than one data source, errors may compound, affecting the entire analysis. It’s crucial to recognize that GIS data is inherently uncertain and prone to error. Steps should be taken to minimize and account for errors by using multiple data sources, validating and cross-checking data, and being transparent about limitations or assumptions in the analysis.
The use of metadata, which provides information about the data, is a valuable tool for GIS users. Consulting metadata can help users understand more about the data they are using and avoid adding additional errors to imperfect data. Good metadata should include basic information such as the age of the data, origin, area covered, scale, projection system, accuracy, and format.